Laminar - Observability for LiteLLM with Laminar
What is Laminar
Laminar is a comprehensive open-source platform for engineering AI agents.
Laminar tracks
- LLM call inputs and outputs,
- Request and response parameters, such as temperature and top p,
- Token counts and costs,
- LLM call latency.
Example complex LiteLLM trace on Laminar:

View a version of this guide in Laminar docs.
Getting started
Project API Key
Sign up on Laminar cloud or spin up a local Laminar instance, create a project, and get an api key from project settings.
Install the Laminar SDK
pip install 'lmnr[all]'
Set the environment variables
import os
os.environ["LMNR_PROJECT_API_KEY"] = "<YOUR_PROJECT_API_KEY>"
Enable tracing in just 2 lines of code
import litellm
from lmnr import Instruments, Laminar, LaminarLiteLLMCallback
Laminar.initialize(disabled_instruments=set([Instruments.OPENAI])
litellm.callbacks=[LaminarLiteLLMCallback()]
Laminar wraps every LiteLLM completion/acompletion call and automatically instruments major provider SDKs. Since LiteLLM uses OpenAI SDK for some of the LLM calls, we disable Laminar's automatic instrumentations of OpenAI SDK to avoid double tracing.
Run your application
Once you've initialized Laminar at the start of your application, you can make any calls to LiteLLM, and they all will be traced.
import litellm
response = litellm.completion(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": "What is the capital of France? Tell me about the city."
}
],
)
Here is what this trace may look like on Laminar.
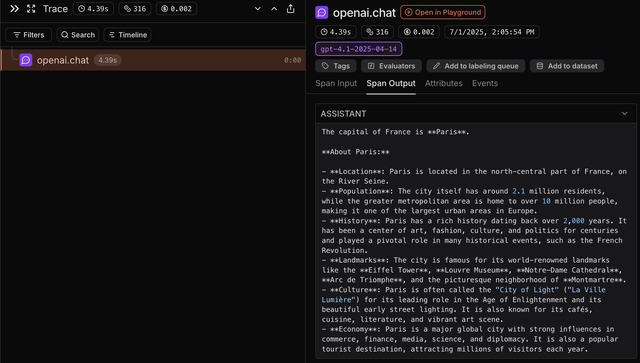
Direct link to the trace.
Support
For any question or issue with the integration you can reach out to the Laminar Team on Discord or via email.